👀 Watch this for a quick intro!
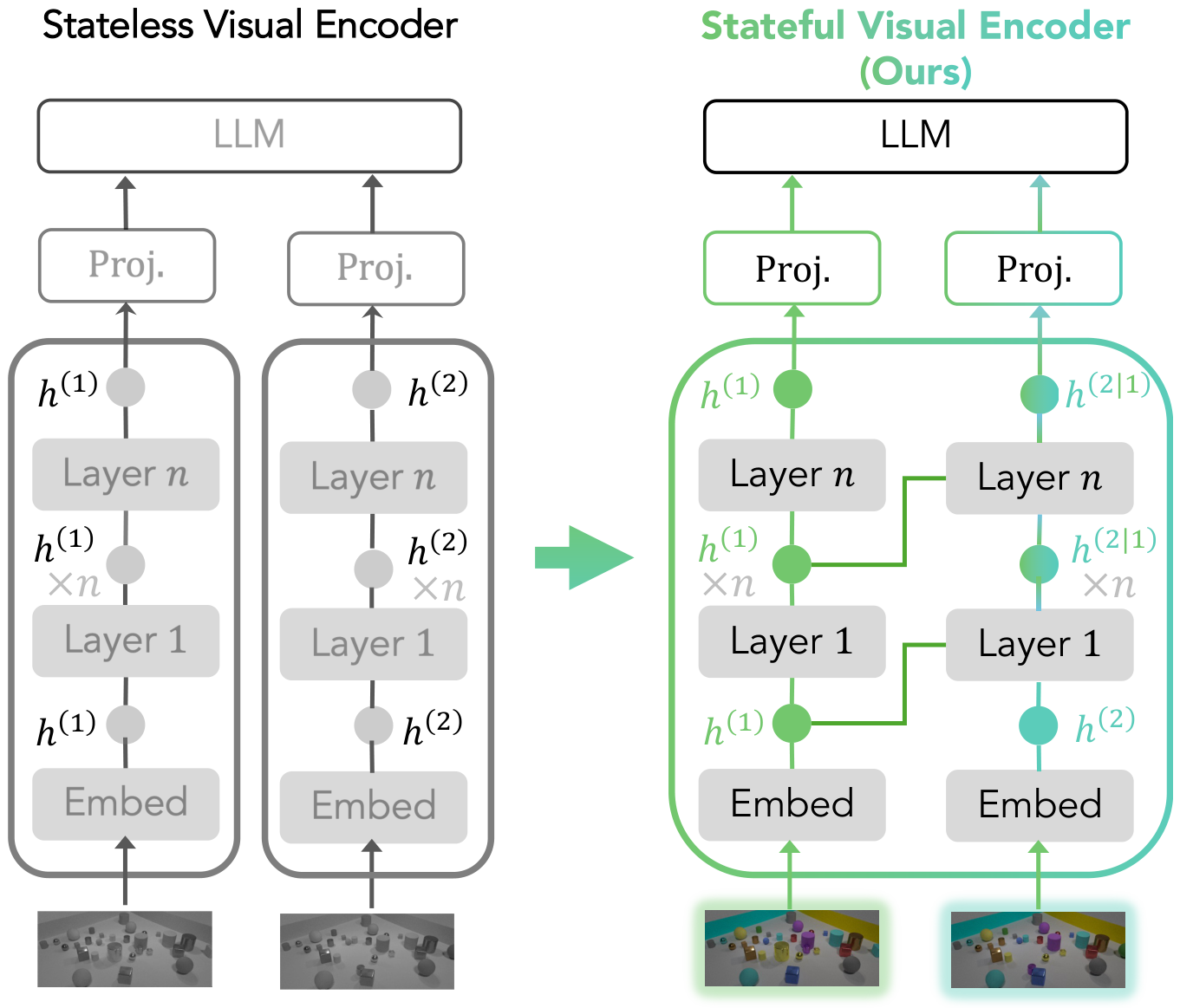
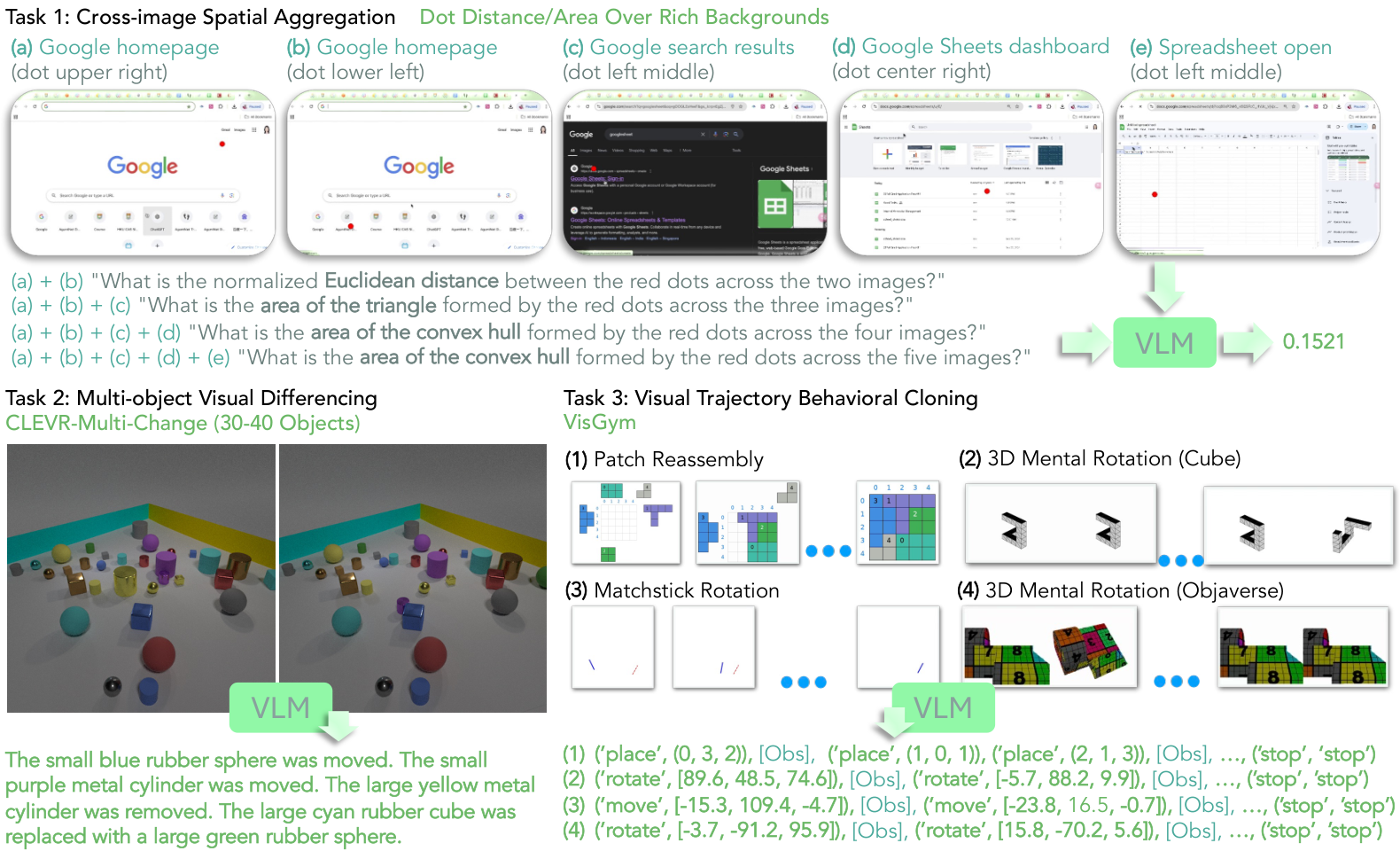
Vision-language models are increasingly used in multi-image, multi-turn agentic settings where decisions depend on visual changes. Yet in existing open-weight VLMs, visual comparison happens only inside the language model — the visual encoder itself remains stateless, encoding each image without access to prior visual context. As a result, small but task-critical changes may be attenuated before the language model can compare them. We introduce a Stateful Visual Encoder (SVE), which conditions each visual representation on prior visual features. Under supervised finetuning, VLMs equipped with SVEs achieve consistent improvements on controlled tasks involving cross-image spatial aggregation, multi-object visual differencing, and visual trajectory behavior cloning — and these gains hold across input resolutions, language-model sizes, and VLM backbones. On real-world tasks (longitudinal radiology, fine-grained image comparison, and remote sensing), SVEs consistently improve generalist VLM baselines and can match or surpass specialized models.
A simple architectural extension that injects cross-image interaction inside the visual encoder of open-weight VLMs — no new backbone, no full retraining.
Initialization and optimization choices — weight cloning, zero-init outputs, and stop-gradient on prior features — that stabilize finetuning and learn state-dependent representations.
Effective and general across controlled comparison tasks, resolutions, model sizes, and VLM families, plus three real-world comparison domains.
We study four ways to make a pretrained encoder stateful — Self-Ext, AdaLN-Zero, Cross, and Cross+FFN. Cross+FFN inserts token-level cross-attention (queries from the current image, keys/values from the previous image) followed by a feed-forward block, and wins across the board.
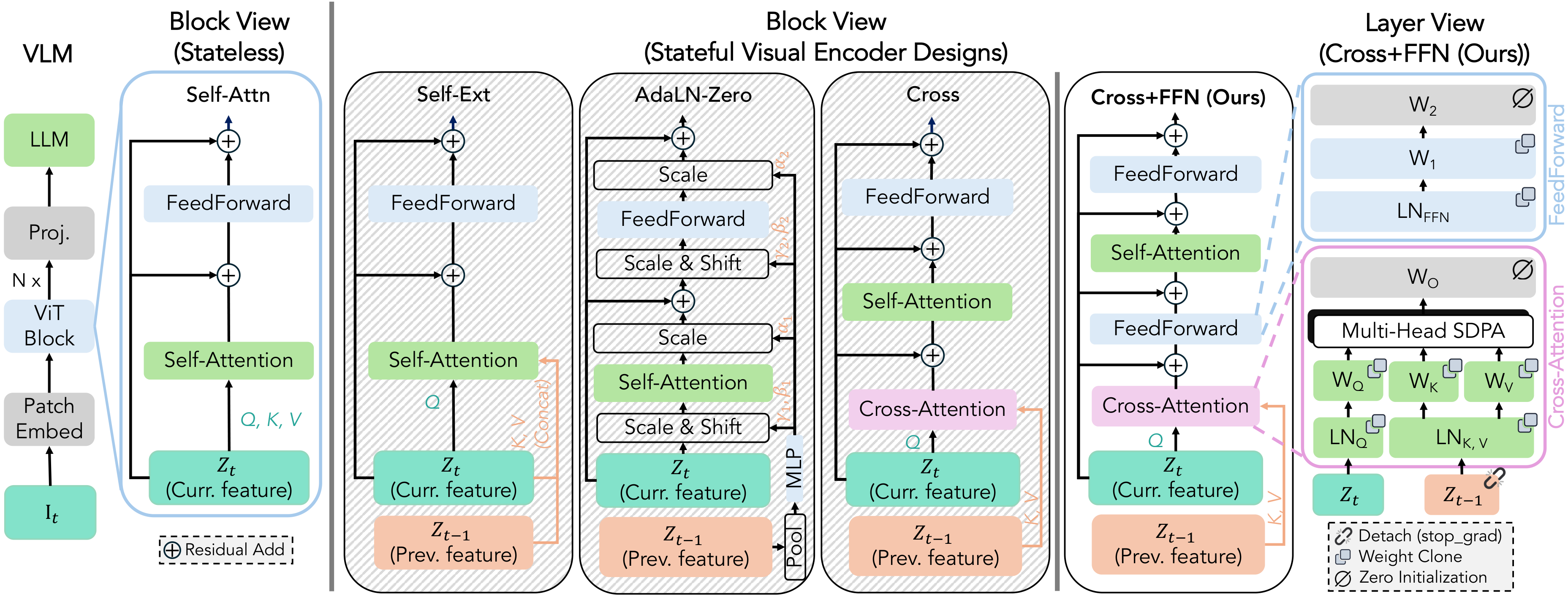
A capacity-matched Self+FFN baseline uses the identical added pathway but cannot attend to the previous image. It improves over stateless — yet stays below Cross+FFN on nearly every task, isolating the gain to statefulness rather than added parameters or FLOPs.
MAE / RMSE (×10⁻²), averaged across dot-distance & polygon-area tasks. Lower is better.
| Method | MAE ↓ | RMSE ↓ |
|---|---|---|
| Baseline (Stateless) | 1.15 | 1.60 |
| Self-Ext. | 1.44 | 2.02 |
| AdaLN-Zero | 1.17 | 1.60 |
| Cross | 1.03 | 1.39 |
| Cross+FFN (Ours) | 0.72 | 0.96 |
CLEVR-Multi-Change (higher better) and VisGym perplexity (lower better).
| Method | CIDEr ↑ | Acc ↑ | VisGym PPL ↓ |
|---|---|---|---|
| Baseline (Stateless) | 529.5 | 91.1 | 2.074 |
| Self-Ext. | 538.1 | 92.5 | 2.132 |
| AdaLN-Zero | 531.8 | 91.4 | 2.069 |
| Cross | 515.0 | 89.3 | 2.009 |
| Cross+FFN (Ours) | 543.9 | 92.7 | 1.944 |
VisGym PPL shown for the 3D Mental Rotation (Cube) task; Cross+FFN improves all four VisGym tasks.
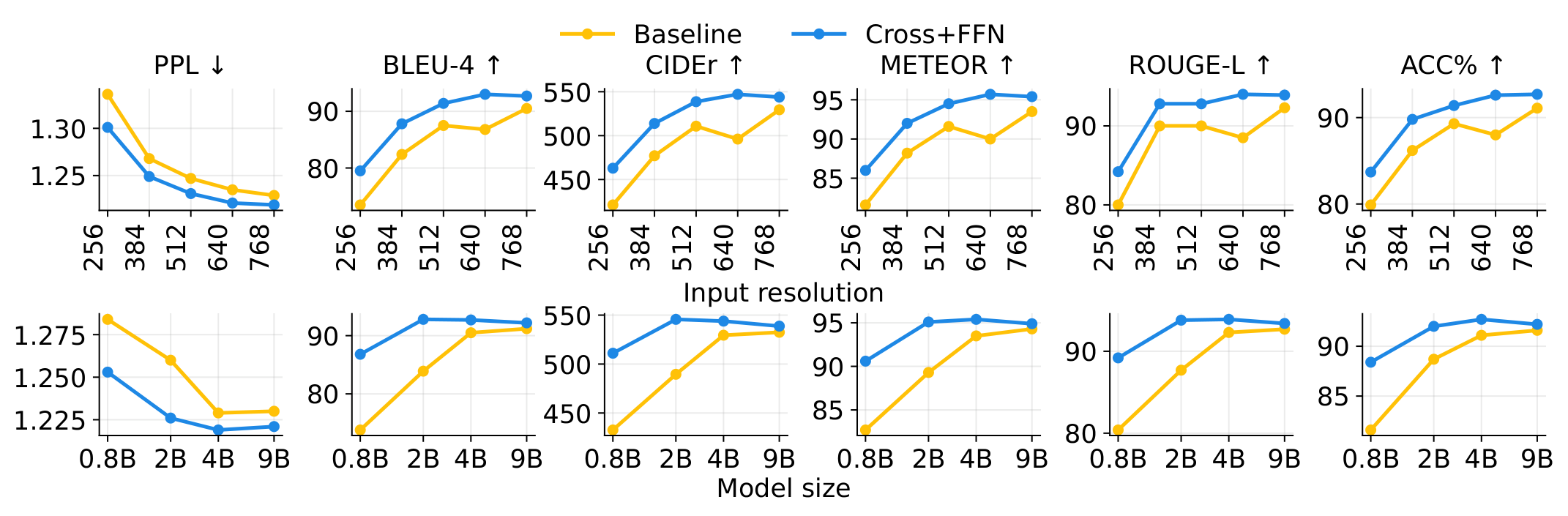
On multi-object visual differencing, SVE beats the stateless baseline from 256² to 768² resolution and from 0.8B to 9B parameters — and smaller SVE models can match or outperform much larger stateless ones.
CLEVR-Multi-Change (30–40 objects). ▲ = improvement over each backbone's stateless baseline (+SVE shown).
| Backbone | PPL ↓ | BLEU-4 ↑ | CIDEr ↑ | METEOR ↑ | ROUGE-L ↑ | Acc ↑ |
|---|---|---|---|---|---|---|
| Qwen3-VL-4B | 1.268 ▲.004 | 82.5 ▲2.5 | 482.1 ▲15.1 | 88.6 ▲1.3 | 86.8 ▲1.5 | 87.3 ▲.7 |
| Qwen3.5-4B | 1.219 ▲.010 | 92.7 ▲2.2 | 543.9 ▲14.4 | 95.4 ▲1.9 | 93.9 ▲1.6 | 92.7 ▲1.6 |
| GLM-4.6V-Flash | 1.236 ▲.005 | 92.4 ▲.7 | 542.0 ▲3.8 | 95.0 ▲.4 | 93.6 ▲.4 | 92.2 ▲.1 |
| InternVL3.5-4B | 1.332 ▲.026 | 68.2 ▲1.7 | 389.5 ▲11.5 | 77.8 ▲1.1 | 76.3 ▲1.2 | 77.4 ▲1.8 |
| Gemma-3-4B | 1.316 ▲.083 | 68.4 ▲8.0 | 387.0 ▲45.6 | 78.0 ▲5.9 | 76.3 ▲5.9 | 77.9 ▲7.9 |
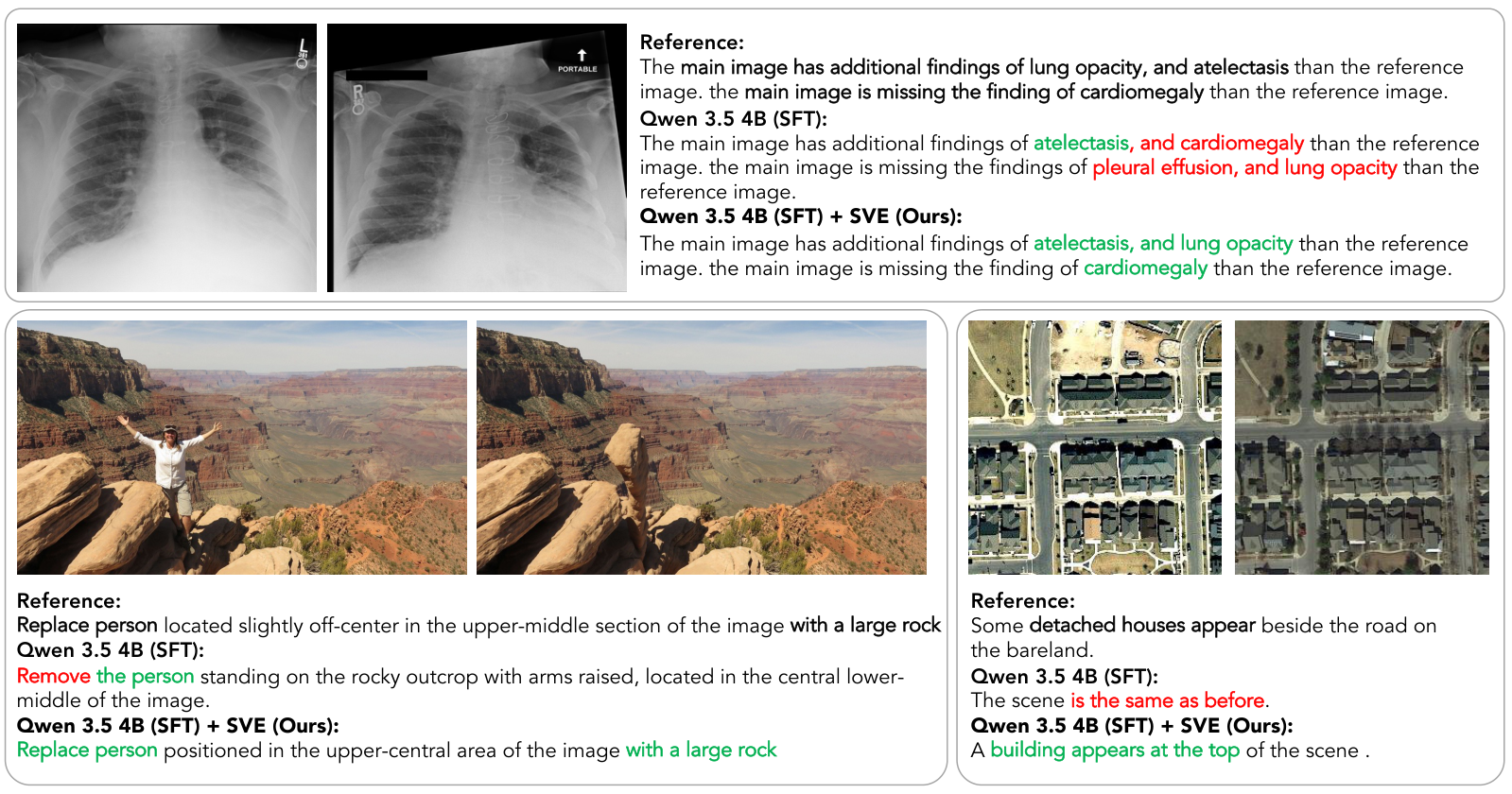
Captioning + RATE-style finding-level F1 over 27 chest findings.
| Method | CIDEr ↑ | R-L ↑ | Micro F1 ↑ | Chg Acc ↑ |
|---|---|---|---|---|
| Qwen3.5-4B (SFT) | 145.1 | 62.7 | 31.55 | 86.83 |
| + SVE (Ours) | 178.9 | 66.3 | 32.20 | 89.21 |
MLLM-as-judge pairwise preference counts.
| vs. Baseline | Base Win | Tied | SVE Win |
|---|---|---|---|
| Reference instruction | 296 | 758 | 346 |
| Qwen3.5-4B (SFT) | 171 | 1020 | 209 |
SVE improves the generalist baseline and surpasses all prior specialist models. Sm* averages B4 / M / R-L / C.
| Method | BLEU-4 ↑ | METEOR ↑ | ROUGE-L ↑ | CIDEr ↑ | Sm* ↑ |
|---|---|---|---|---|---|
| Best prior specialist models | |||||
| Chg2Cap | 62.98 | 39.42 | 74.34 | 136.25 | 78.25 |
| PromptCC | 63.54 | 38.82 | 73.72 | 136.44 | 78.13 |
| SAGE-CC | 65.50 | 39.92 | 74.77 | 137.50 | 79.42 |
| SACNet | 65.57 | 40.30 | 75.68 | 138.34 | 79.97 |
| Generalist VLMs | |||||
| Qwen3.5-4B (SFT) | 60.70 | 39.42 | 76.03 | 142.26 | 79.60 |
| + SVE (Ours) | 61.33 | 39.91 | 76.26 | 144.35 | 80.46 |